
Companion Episode: You can really get to know someone by leafing through their diary
In Neutrinowatch, Jeff and I often comment to each other about the Herculean effort of making simple-seeming ideas work. Coming from the traditional podcast world, we’re used to clicking a button in our audio software to make something happen – a change in volume, adding a reverb effect or a cross-fade. For Neutrinowatch, it can feel like we’re building a button and then adding a Heath Robinson system of pulleys, levers, and ping-pong balls that will push the button every morning without our further intervention.
An apt visual metaphor.You can really get to know someone by reading through their diary took us at least eight months to create. Let me explain why. To do that, I’ll recap what’s going on in the episode, and then I’ll focus on elements that took a lot of time, and why. Mostly because this episode is a fucking swan and I want to draw your attention to its rapidly moving legs
Note: The episode started life as Year of Poems for reasons that will hopefully become obvious, so I’ll call it that, because its finalized title is long—deliberately so, because I wanted something that helped to explain the action in the scene. Jeff is not to blame for this, he begged me to be sensible.
In Year of Poems we hear the low hum of machinery that we heard in the background in The Most Popular Podcast In The Universe, Tomorrow as footsteps approach, and a door opens. We hear someone drink a slug of coffee and start up a computer. Then they click “play” and some music starts, and they start typing. We transition “into the computer” and we hear the words being typed: John Welles’ diary (so, by now it should be clear that it is John Welles, Neutrino-watcher extraordinaire, that we’re spending time with). When the diary entry is complete, we transition back into the room, and John stops typing, pauses the music, and leaves the room. Wendy (the station AI) checks to see if he’s gone, and when it’s clear he has, she restarts. We hear music again, but it’s a simple loop of what we heard before — as the episode continues, the loop becomes more and more choppy. We transition back into the computer, and hear a “remixed” version of John’s diary, interspersed with commentary from Wendy. The music reaches a crescendo as the speech recedes, and we hear the original piece of music that John played at the start of the episode.
There are five main elements that change each day:
- John’s Diary entry
- The “remix” of John’s Diaries
- Wendy’s reaction
- The music
- The “remix” of the music
Flowing from these are things that have to change every day as a result. I’ll talk about those five crucial changes first.
1. John’s Diary
I started my audio life as a songwriter, where the creative cycle around a song follows a period of days or weeks, but rarely months. In 2018, I wrote and recorded 40 songs; when I did Tim Clare’s 100 day writing challenge, I was writing for ten minutes every day for over three months (with a break in the middle). Neutrinowatch isn’t like this – even a simple episode takes months to build.
I decided this episode could be an opportunity for me to build a creative habit, and write 366 poems – which morphed into writing 366 diary entries for John Welles — a mix of poems, in-world fiction, and actual journal entries as myself or in character. I wrote more than one every day and barely revised. At time of writing, I still have a few to finish, but I’m far enough ahead that Neutrinowatch is unlikely to catch up with me.
Writing nearly four hundred poems was the easy part.
2. The “remix” of John’s Diaries
To stop the episodes repeating after a year (well, 366 days), I decided I’d create new poems in the second half of the episode by swapping out lines from the poems from other days.
Let’s take today’s as an example. Here’s the original “poem”/entry:
Parrot
I don’t know how the gears grinding don’t break
That is the human condition
Ultimate resilience
I think birds probably have terrible lives
But they don’t know it
The remixed version looks like this:
Parrot
When each word is a brick
I don’t know how the gears grinding don’t break
Constantly being hammered by waves
Unclear
I think birds probably have terrible lives
And how much is blind luck
I’ve bolded the lines that are borrowed from the other 365 poems that weren’t selected for today’s episode. For example, the line When each word is a brick is taken from an entry called “People Like The Sound”; and Constantly being hammered by waves is from “Notes from a Beginner Surfer”. It works a bit like this, taking the template (length and default text) from “Parrot” and swapping lines out:
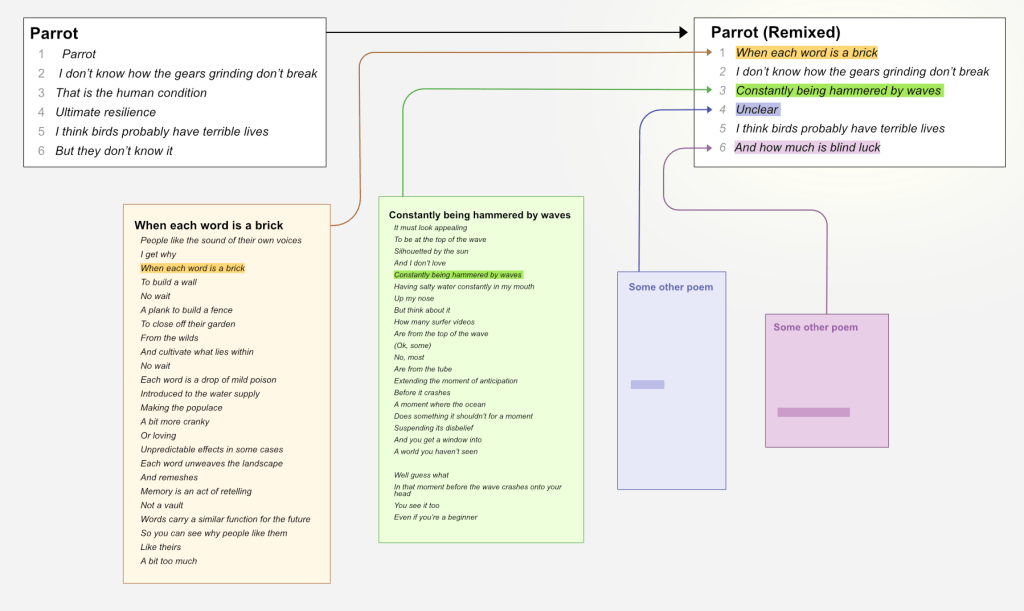
The probability of each line being replaced gets bigger as we move through the poem —so it’s more likely that later lines are replaced.
That still wasn’t the hardest part.
There are a couple of ways of implementing this in audio. The “easy” way is to record each line (separately). That would probably generate several hours of audio. You’d then find a sensible way to export, organise, label and process over 6000 separate files. We did the much harder mechanism, which was to train a text to speech (TTS) model that could take text input and return audio in my specific voice (i.e. I “deepfaked” myself). I’m not going to go into the ins and outs of this —mainly because our method is held together with duct tape and spit — but having a fully trained Martin Austwick Voice Model (TM) means we can do more complex stuff like swap out vocabulary and get the model to say things I’ve never said. Which is scary too, I guess. It involved compiling quite a lot of audio and then making a model that could run offline without my intervention.
I secretly hope people don’t notice it’s a voice model, though. It messes up words and says “lever” weird, but generally it’s pretty unobtrusive. I’d be very curious to know whether (and at what point) people noticed it wasn’t the “real me”.
3. Wendy’s Reactions
Wendy reacts to the poems that she’s “remixed”. That meant writing a bunch of options for Wendy too – they’re mostly designed to be meditations on how friendships are made, or how she wants to build them. Some are creepy:
You can really get to know someone
I’m close by when you sleep
Not very close
I’m not completely insensitive
To your boundaries
Your need for privacy
I live here too, though
I’m just in the next room
Watching over the perimeter
Keeping you safe
You can really get to know someone
Some are lighter:
You can really get to know someone
Studying together
Study buddies
I like the way that sounds
“Study buddies”
You can really get to know someone
Wendy’s just trying to understand people, really.
4. Music choices
Ok, the difficult part was over. Next up: music. One of the things we talk about when we’re planning new episodes of Neutrinowatch (twice a year or however long it takes) is combinatorial advantage. If there were a Neutrinowatch bingo card, “Combinatorial Advantage” would be the free spot in the middle. It’s a tool we leverage a lot. A LOT.
Combinatorial Advantage can be illustrated with a simple scene —let’s say you walk into the room and see a dog eating a bone. Let’s say the animal could be a dog, a lion, a cat, a griffon, or a zombie. Now there are 5 possible variations. Let’s say the thing that’s being eaten could be a bone, a bowl of soup, a steak, a corncob, or a lollipop, (irrespective of the animal eating it)- now we have five animals and five foodstuffs, giving 25 scenes. Let’s say the animals can be five different colors (125 scenes) and wearing 5 different fun hats (625 scenes). These are ways to quickly generate wider scene options: 5×4 (20) options leads to 54 (625) variations.
This can be an incredibly cheap way to create a lot of variation, in both senses of “cheap”, but I was also interested in the potential of emotional combinations, and using music to create those. Maybe you’ve seen a movie trailer recut to make The Shining seem joyous or Charlie and The Chocolate Factory seem terrifying (ok the original is kinda creepy); a big part of those recuts is music. Music under the same images can shift historical drama to horror to romance to thriller to melodrama. I wanted to experiment with that here, and have some different musical moods and instruments that would recontextualise the text you’re hearing. To this end I created a 30 minute piece of music that covered intense metal, relaxed jazz, mournful strings, bouncy electronica, aspirational folk, expectant minimalism, and probably some other stuff I’ve forgotten. Because 2-3 minutes of music is used in each episode, we get just one of those moods; or sometimes a transition between moods. And whether that mood is light or heavy, playful or romantic, it will (I hope) change the context of the words. Also, using the Text To Speech model means they can’t really be modulated in the normal way we express tone —with our voices, with performance.
5. The “remix” of the music
I wanted to have something that would help indicate to the listen that the second half of the episode (after John has left the room —the computer starting up, the music, the “remixed” poem, and Wendy talking) are somehow being driven by Wendy without John’s further intervention, and to echo the “remix” and rejuxtaposition of the poem. The method I used is something I called “lumpy synthesis”, because it bears some resemblance to granular synthesis, but I don’t think I invented it so it probably has a different name. This is how it works:
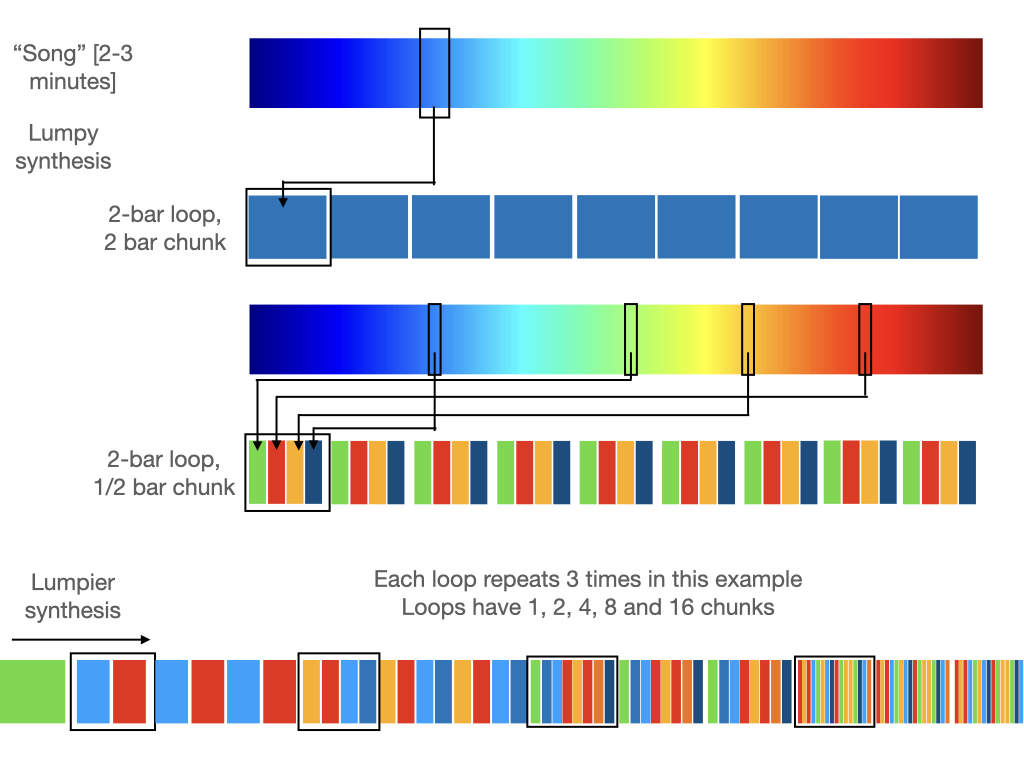
The code samples 2-3 minutes from the 30 minute piece — I call this the “song” of the day and it’s what the first part of the episode uses. Lumpy synthesis randomly samples “chunks” from the “song” —these chunks are some fraction of a bar long. They can be any length but here I use factors of 2 —2 bars, one bar, 1/4 bar, 1/16 bar etc —that way they lie on a beat, so whatever we create will sound rhythmic. Then I assemble those segments into a loop that’s a set number of bars long, and loop it.
So, for example, let’s say we want a loop that’s 2 bars long, that we will repeat. We could take a random 2 bar segment and loop it, or we could choose chunks 1/2 a bar long, and assemble 4 of them to make a 2-bar loop.
The remix does something a bit more complicated —it uses loops 2 bars long, and then loops that 6 times (enough so it starts to feel comfortable and familiar to the listener – I’ve only shown it repeating 3 times in the above diagram for reasons of space). Then, it reduces the chunk size to 1 bar but keeps the loop length at 2 bars —i.e. it glues together two random one-bar sections to make a loop. Then it plays that 6 times. Then it sets the chunk size to half a bar —i.e. it picks 4 random 1/2 bar sections and glues them together to create a 2 bar loop —and loops that 6 times. Each time the loop stays 2 bars long, but the segments making up the loop get half as long. It keeps doing that until it has enough music. This leads to a piece that gets choppier and choppier throughout, until it’s chaos, at which point we crossfade to the original piece of music to produce a more placid ending.
Conclusion
So that’s the episode.
And that, dear reader, is what a pair of swan’s legs look like.
Postscript
If you’re even more interested in the nitty-gritty, I also mentioned that there are “consequences” to making an episode this way. Things like:
Adding reverb on the fly via code
The spoken audio is different every day. Because I have the text of the poems, I *could* pre-render all of the audio in advance, with reverb (echo) effect applied to the speech to place it in the appropriate scene/space; but it gets very complex to organise the resulting thousands of audio files. The other way is to generate the speech audio each time an episode is produced and add reverb at the same time. The first poem uses a long reverb I captured in the stairwell of the 1950s block of flats I live in in London to represent “the infinite space inside the computer”. The second (remixed) poem has that too, but first goes through a processor (technically a convolution) designed to make it sound like a crappy radio, to hint that something is different about this journal entry.
(All these rely on convolution reverb which is not fast – maybe 5x realtime? – but it does add up to creating quite long render times for this episode, especially with the TTS model).
The music needs to go through similar effects. In the first scene, it uses the same radio effect, and then a reverb which sounds like John’s lab. The “inside the computer” scenes need that big reverb sound. Because this is pre-written, I did experiment with rendering these out as different audio files and mixing them when the episode was generated, but that made making any changes to the music a pain, so all the reverbs are added on the fly, the same way as the vocals are treated.
Figuring out the transitions in the music
The “song” starts playing partway through the first scene (in the lab), goes all the way through the second scene (where we’re inside the computer listening to today’s diary) and ends partway through the third scene (when John turns off the music and leaves the room). The length of the second scene depends on the poem, so the total length of the “song”, and where it transitions between scenes/effects, varies each day. And obviously the song itself is different each day. So those timings need to be calculated on the fly. The same is true for the song “remix” – its length varies with the remixed poem, and I had to time and process transitions from the “lab” to the “computer”.
Dealing with Crossfades in Lumpy Synthesis
When you cut stuff up fast, it sounds clicky, so you need ways to crossfade the lumpy synthesis. You also need to make sure you’ve cut long enough segments that the crossfades don’t mess up the rhythm. You also need to make sure that the crossfades aren’t longer than the segments as they get shorter and shorter.
Timing the speech
Did I mention that the speech is timed so that each line starts in time with the music? That had its own method too!

Leave a comment